松井茂は自転車映画ではない映画から自転車を探り出す。最近の記事ではテレビドラマ『孤独のグルメ』を取り上げており、約80話のうち主人公が自転車に乗るのは1話のみと言うのだから感心する。それでは、ある映画に自転車が登場するのか否かを調べるには、どうすれば良いのだろう。もちろん、目を皿にして映画を見れば良い。2倍速でもなんとかなるだろう。だが、それは面倒で退屈だ。
そこで、面倒で退屈なことならAI(人工知能)に任せるに限る。特に画像から何かを見つける画像認識はAIの得意技であり、指紋認証や監視カメラなど応用例も多くある。ここではAIの中でも最新のディープ・ラーニング(深層学習、機械学習の手法のひとつ)による物体検出アルゴリズムを用いて、映像から自転車を探し出してみたい。まずは先の『孤独のグルメ』を分析する。
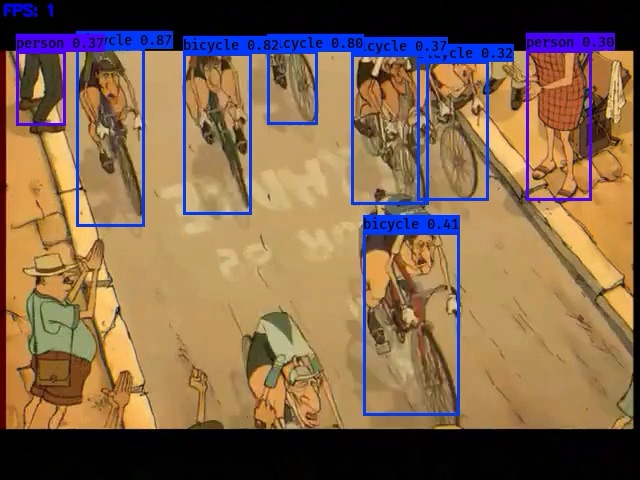
処理結果は一目瞭然、映像に現れた人物、自転車、自動車などが矩形で囲まれ、その名称と信頼度が添えられる。間違った判定が僅かにあるものの、ほとんどの検出が的確であることが分かる。しかも、上部だけ映った自転車がそうであるように、物体の一部だけでも認識されている。ちなみに今回用いた学習済みモデルは80種類なので、これら以外の物体は検出できない。
{kind=link}
次に、フレーム(映像の一コマ)ごとに自転車が画面に占める割合に信頼度を掛けた数値を求める。自転車が映っていなければ0.0で、画面に対して自転車が半分の大きさなら0.5といった数値になる。複数の自転車が映っているなら、各数値を合算する。これを時系列に沿って棒グラフにすれば、映像の進行に沿った自転車の出現が把握できる。棒グラフが高いほど自転車が大きく、あるいは数多く映っている。

この手法では画像として物体を検出しており、文脈や意味を判断している訳ではない。例えば、0’57”からは主人公の上半身がズームアップされており、自転車は検出されない。だがこれは主人公が自転車に乗って快走するシーンだ。つまり、ディープ・ラーニングは前後関係や状況を類推できないわけだ。主人公の独り言でも自転車に乗っていると分かるが、音声もまた物体検出には用いられない。
{kind=link}
また、極端にデフォルメされたアニメーション「ベルヴィル・ランデブー」では、何も検出されないか、誤って認識されてしまう。学習モデルの素材は実際に存在する物体の写真なので、それからから懸け離れた画像を正しく扱えないことになる。若干ながら自転車の認識率が良いのは、そのデフォルメ度が低いからだろう。逆に、主人公が伏したテーブルを時計と判断するのはウィットが効いている。
{kind=link}
{kind=link}

このように物体認識は制約があるものの、概ね自転車検出機として機能しそうだ。問題は処理の負荷が高いことで、MacBook Pro(Intel Core i9/2.9GHz)では、先の「孤独のグルメ」の冒頭部分2分13秒に対して処理時間は42分11秒であった。これは余りにも遅いが、学習モデルの限定、類似フレームの無視、GPUの使用といった方策で高速化できるかもしれない。

さらに問題であるのは、分析対象となる映像ソースだ。DVDやストリーミング配信があっても、それらはコピー・プロテクトされていて利用できない。抜け道は映像を再生している画面を別のカメラで撮影すること。しかし、それも手間がかかり、大量になると現実的ではない。URLで映像ソースが得られるのが理想だろう。「One Got Fat」のようなパブリック・ドメイン映像が増えて欲しい。

さて、今回用いた物体検出方法はYOLOという手法で、そのバージョン3をKerasとTensorFlowなるライブラリを使ってプログラミング言語Pythonで記述したqqwweee氏のkeras-yolo3を利用した。このプログラムを利用するのは簡単であるものの、その実行環境を整えるのが大変かもしれない。ここでは深入りしないでおくが、実行環境が整えばターミナルで以下のコマンドを打つだけで良い。
python yolo_video.py --input [分析するビデオのファイル・パス] --output [分析結果のビデオのファイル・パス] | tee [分析結果のテキストのファイル・パス]
例えば、mediaフォルダにあるtest.movというビデオを分析するには、以下のようになる。
python yolo_video.py --input media/test.mov --output media/test-result.mov | tee media/test-result.txt
これで指定したビデオの分析が始まり、Pythonのウィンドウに分析結果の画像が、ターミナルに分析結果のテキストが表示されるとともに、それぞれのファイルに出力される。分析結果のテキストは以下のような内容で、最初の2行に続いてフレーム毎に検出された物体の情報が得られる。これは物体の名称、検出の信頼度、そして物体を囲む矩形の左上と右下の座標となっている。
model_data/yolo.h5 model, anchors, and classes loaded. !!! TYPE: <class 'str'> <class 'int'> <class 'float'> <class 'tuple'> (416, 416, 3) Found 3 boxes for img bicycle 0.72 (55, 212) (408, 352) person 0.97 (554, 47) (638, 300) person 1.00 (196, 83) (345, 353) 0.49851540199597366 (416, 416, 3) Found 4 boxes for img tie 0.48 (249, 152) (265, 200) bicycle 0.69 (54, 212) (406, 352) person 0.97 (554, 47) (638, 300) person 1.00 (195, 85) (343, 353) 0.5130787439993583 (416, 416, 3) Found 2 boxes for img bicycle 0.99 (171, 65) (640, 443) bicycle 1.00 (0, 65) (365, 411) 0.5196566439999515 (以下省略)
そこで検出された物体が自転車(bicycle)であれば、矩形の面積を求めて画像全体の面積で割り、信頼度を掛けた値をフレーム毎に合算してテキスト・ファイルに出力する。このような処理を行うPythonプログラムは以下の通り。あらかじめ入力ファイルと出力ファイル、そして画像の面積をプログラム中に指定しておく(1〜3行目)。最後にスプレッドシートなどでグラフ化を行えば一連の作業は完了だ。
input_path = 'media/test-result.txt'
output_path = 'media/test-result.csv'
image_area = 640.0 * 360.0
with open(input_path) as input:
with open(output_path, mode='w') as output:
lines = input.readlines()
bicycle_ratio = 0.0
for i in range(len(lines)):
items = lines[i].split()
if items[0] == 'bicycle':
accuracy = float(items[1])
x1 = int((items[2])[1:-1])
y1 = int((items[3])[0:-1])
x2 = int((items[4])[1:-1])
y2 = int((items[5])[0:-1])
ratio = (x2 - x1) * (y2 - y1) / image_area * accuracy
bicycle_ratio = bicycle_ratio + ratio
if items[0].replace('.','').isdigit():
output.write(str(bicycle_ratio)+'\n')
bicycle_ratio = 0.0